

はじめに
こんにちは、株式会社 Village AI 取締役 松本 祐輝です。
本シリーズでは、日本酒アプリ「さけのわ」のデータをDataikuで分析してみたいと思います。
今回は、データを取得して加工するところまでやります。
さけのわデータとは
日本酒アプリ「さけのわ」が保有するフレーバーを数値化したデータや人気銘柄情報を公開するプロジェクトです。
利用規約の範囲内で誰でも無料で利用することができ、ECサイトでデータを表示したり、
アプリやサービスを作ったり、データ解析を行ったりすることができます。
Dataikuとは
Dataikuは、データサイエンスと機械学習のためのエンドツーエンドプラットフォームです。
データの準備からモデルの展開までをサポートし、効率的なチームコラボレーションが実現できます。
ビジネスユーザーやデータサイエンティストは、
異種のデータソースからのデータ統合やモデル構築を簡素化できます。
豊富なデータ可視化機能やセキュリティ対策も特長です。
さけのわデータ分析:データ加工編
データの取得
さけのわではユーザーの感想コメントを解析してフレーバーを数値化しており、
このデータに加えてランキング情報を含む以下のデータが公開されています。
- 銘柄ごとのフレーバーを華やか、芳醇、重厚、穏やか、軽快、ドライの6つの観点で数値化したもの
- 銘柄ごとのフレーバーの詳細をタグ化したもの (フレーバータグ)
- さけのわでの人気銘柄ランキング
- その他、銘柄の基本情報
DataikuのAPI Connectプラグインを使って読み込みます。
Plugin: API Connect | Dataiku


データの加工
銘柄に対してフレーバーの数値があるので、分析して、今後の日本酒を注文する際の参考にしようと思います。
具体的には、フレーバーの数値をもとにクラスタリングを行い、各クラスタの特徴を確認します。
データの結合
まず、バラバラになっているデータを結合します。
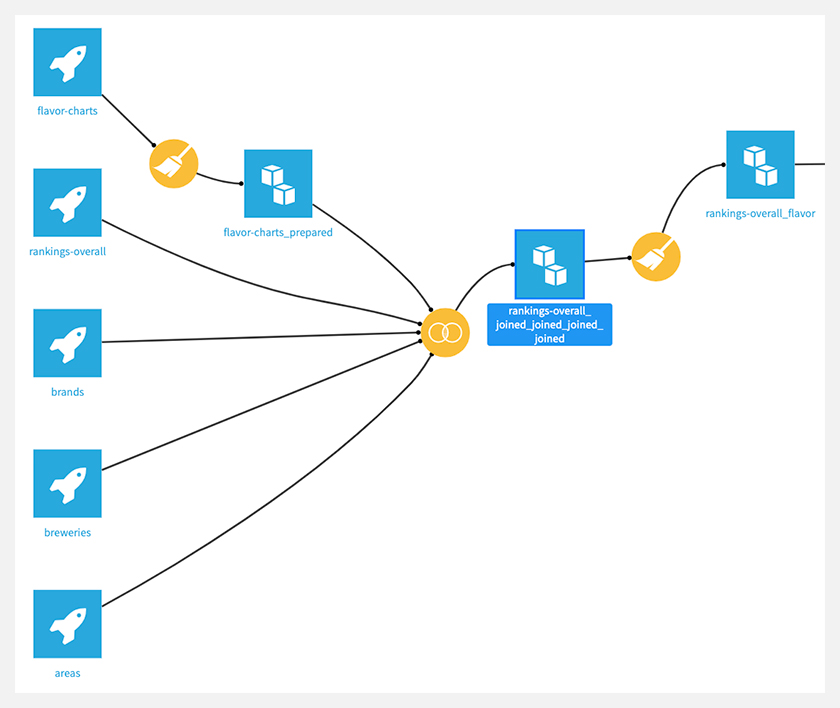
flavor-chartsで繋がってるPrepareレシピは、
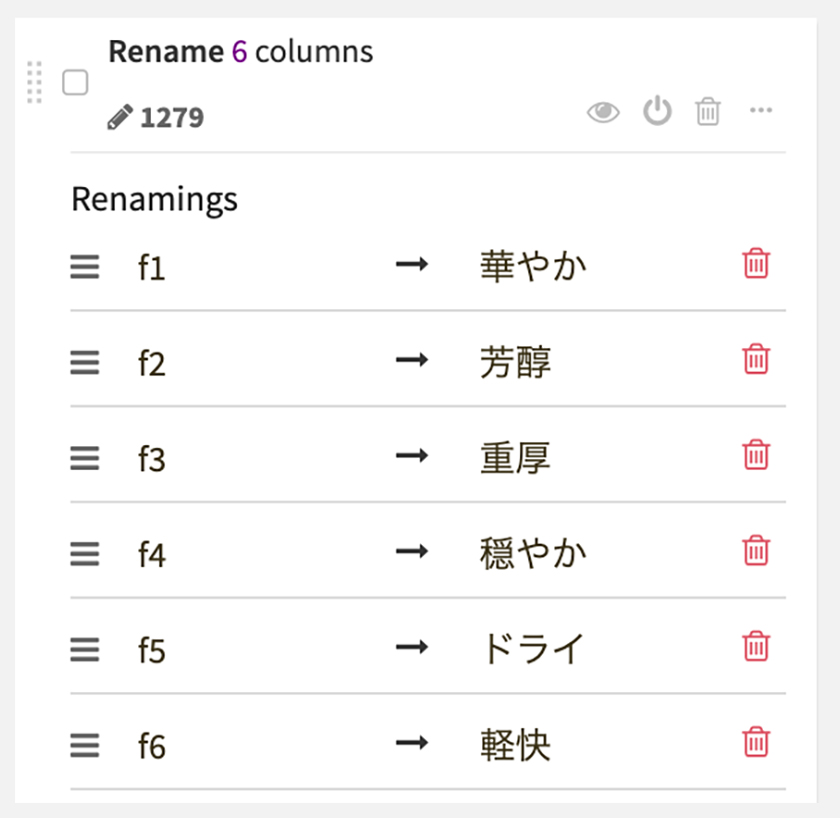
カラム名がf1〜f6となっていたのを、華やか、芳醇、重厚、穏やか、軽快、ドライに変更する処理、
結合後のPrepareレシピは不要なカラムの削除を行っています。
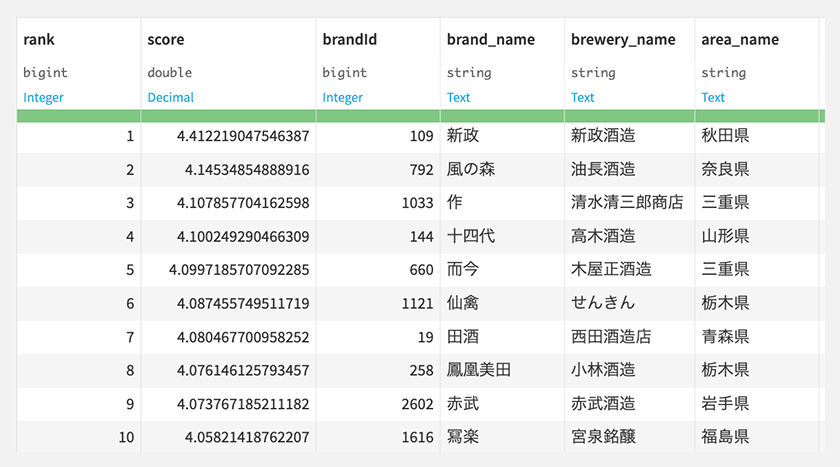
ランキングトップ10は、こんな感じでした。
おわりに
今回は、DataikuのAPI Connectを使って、日本酒アプリ「さけのわ」のAPIからデータを読み込み、
結合するところまで実行しました。
次回は、データの可視化とクラスタリングをやってみたいと思います!
コメント